Enable Apple Silicon GPU to accelerate parallel computing
1. Introduction
Apple Silicon GPU is a powerful GPU that can be used to accelerate parallel computing. It is based on the Metal framework, which is a low-level, low-overhead hardware-accelerated graphics and compute API. It is designed to take advantage of the parallel processing capabilities of the GPU. Therefore, it is a good choice for parallel computing tasks. In fact, it is the first time that developers can consider some real Deep Learning tasks on Mac.
Since the Apple M1 release, Apple Silicon GPU has got enough support from community. PyTorch, the most popular deep learning framework in academic, has released the support for Apple Silicon GPU [1]. TensorFlow, also a very popular deep learning framework that makes a specific optimization for edging devices, has also released the support [2]. What’s more, some popular deep learning models have been re-implemented to optimize for Apple Silicon GPU, such as llama.cpp[3]. A lot of developers are enthusiatic about adventuring the new world of Apple Silicon GPU like Georgi Gerganov. Moreover, Apple has released the Apple Silicon optimized deep learning framework mlx[4].
What is more interesting is that Apple Silicon GPU is even a more financial solution for training and inference in the era of large models. Thanks to the Memory Unified Architecture (MUA), Apple Silicon GPU can share the memory with the CPU, or even SSD. In theory, GPU with larger VRAM is needed to run large models if no specific optimization is applied. So the MUA provides a more financial way to get VRAM, i.e., developers can get GPU with larger VRAM relatively cheaper. That is why open source community is very interested in Apple Silicon GPU.
2. the d2l module
The d2l module is the support lib used in the interactive tutorial “Dive into Deep Learning”[5]. It provides lots of useful wrappers and utilities for deep learning. It is a good choice for beginners to learn deep learning and researchers to prototype deep learning models quickly. The d2l module also provides support for various deep learning frameworks, such as PyTorch, TensorFlow, MXNet, and JAX.
However, d2l has not released the support for Apple Silicon GPU. So we need to modify the source code of d2l to enable the support for Apple Silicon GPU. In this article, we will show you how to modify the source code of d2l to enable the support for Apple Silicon GPU.
3. Code Modification
3.1 For PyTorch
1 | def is_apple_silicon(): |
Use this function to check whether the code is running on Apple Silicon devices. Must pay attention to the fact that torch.backends.mps.is_built() doesn’t necessarily mean MPS is available.
1 | def gpu(i=0): |
Use this function to get a GPU device. If the code is running on Apple Silicon devices, it will return a Metal Performance Shaders (MPS) device. Otherwise, it will return a CUDA device.
1 | def num_gpus(): |
Use this function to get the number of available GPUs. If the code is running on Apple Silicon devices, it will return 1. Maybe this magic number 1 should be changed in the future if Apple releases multi-GPU devices. Otherwise, it will return the number of available CUDA devices.
3.2 For TensorFlow
1 | import platform |
Unlike PyTorch, TensorFlow doesn’t provide a specific API to check whether the code is running on Apple Silicon devices. So we need to use the platform module to check it.
1 | def gpu(i=0): |
Use this function to get a GPU device. If the code is running on Apple Silicon devices, it will return a Metal device. Otherwise, it will return a CUDA device. The support of Tensorflow for Apple Silicon GPU is implemented by adding tensorflow-metal plugin. Therefore, we need to raise a RuntimeError if the code is running on Apple Silicon devices but the tensorflow-metal plugin is missed.
4. Results
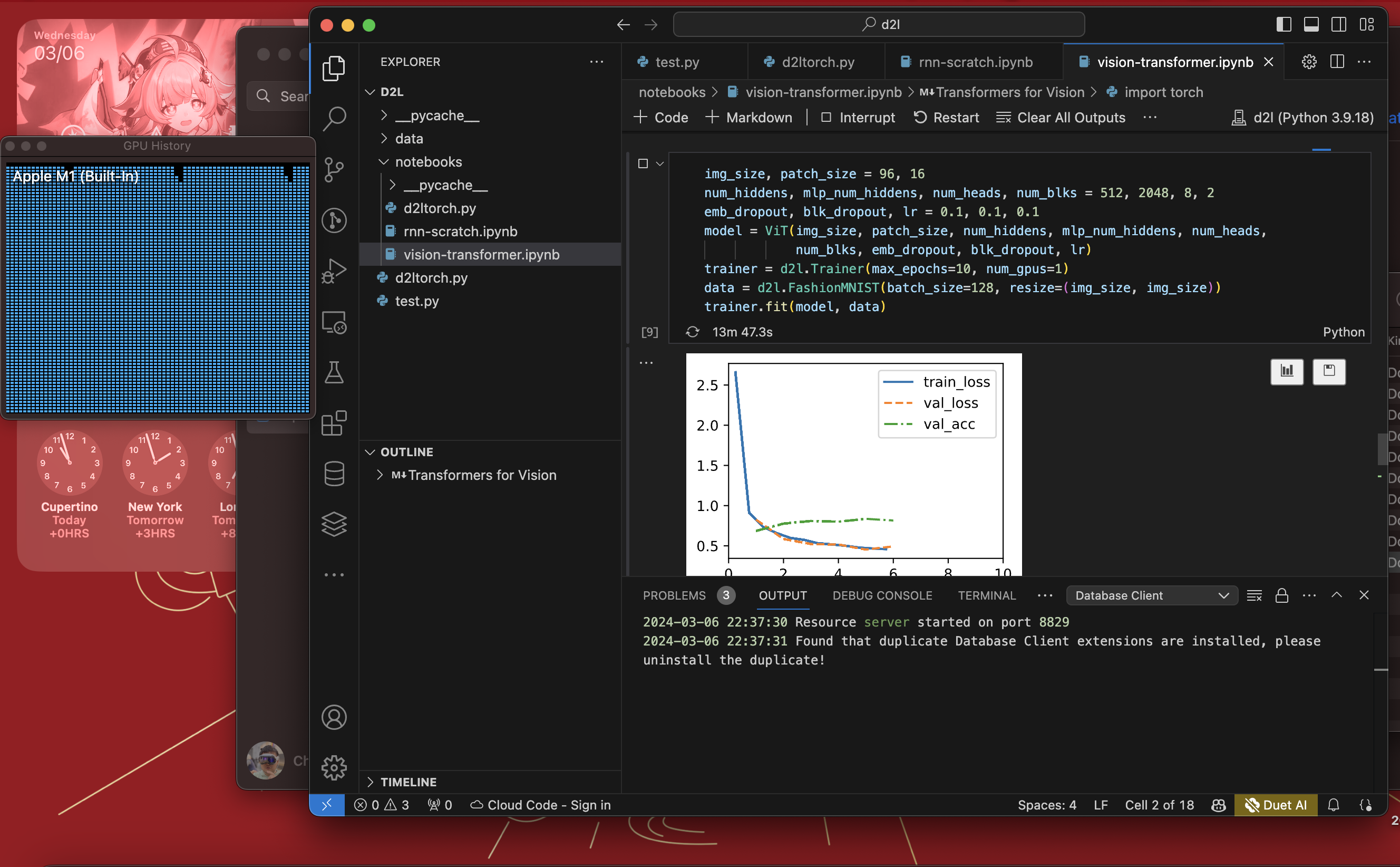
GPU is designed for accelerating parallel computing. And the Transformer model is a typical model that can benefit from GPU acceleration. In general, image dataset’s information is much more than the text dataset. Therefore I designed an experiment to use the d2l module to train a Vision Transformer model on Apple Silicon GPU to test the modification.
The experienment setup is as follows:
- Hardware: MacBook Pro (13-inch, M1, 2020)
- RAM: 16 GB;
- Model Architecture: 2 Transformer blocks, 8 heads, 512 hidden units, and 2048 mlp hidden units;
- Dataset: Fashion MNIST;
- Training setups: 10 epochs, batch size 128, learning rate 0.1, block dropout 0.1, embedding dropout 0.1, and attention dropout 0.1.
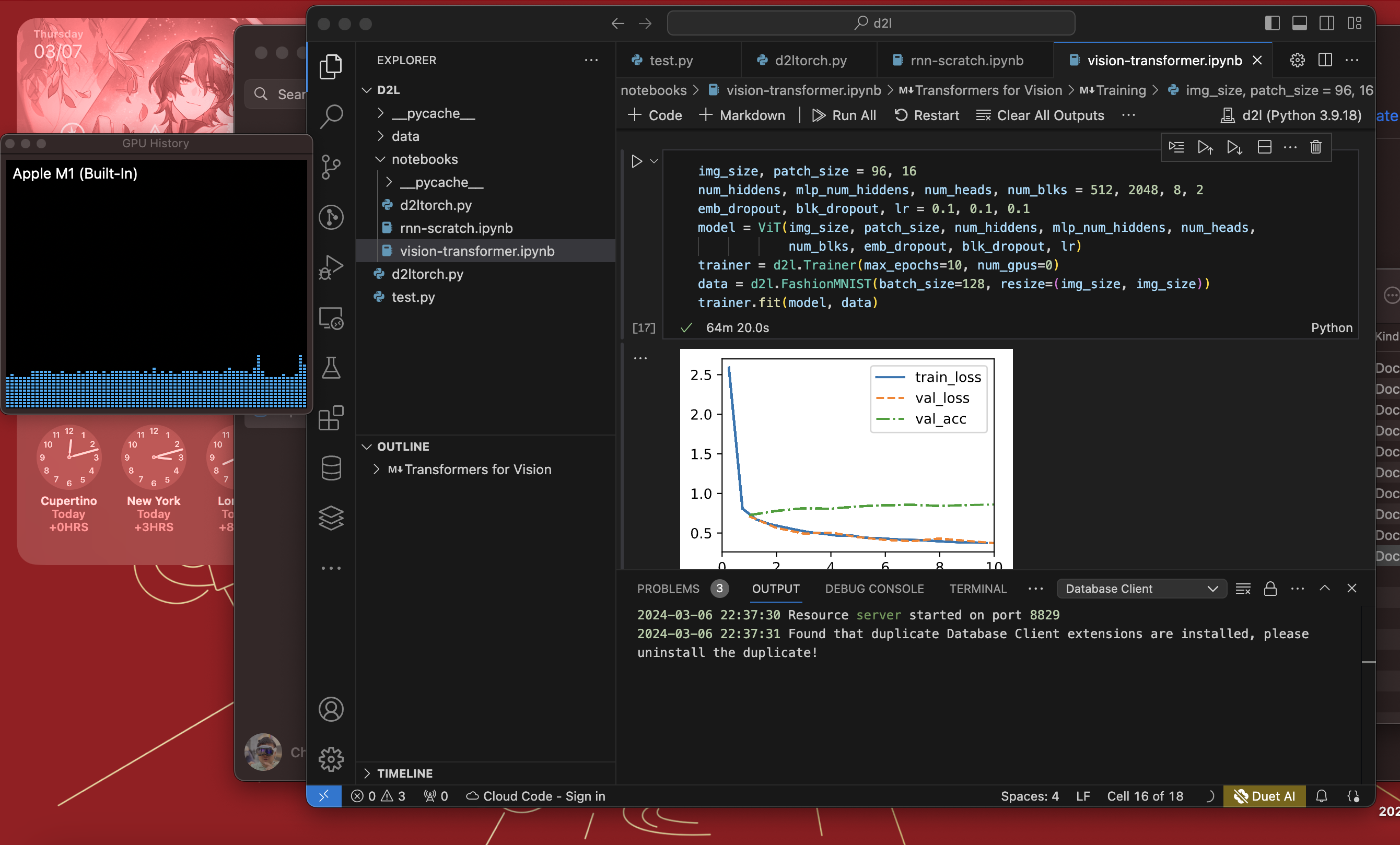
The training process can use GPU acceleration well. With acceleration, it needs 1323 seconds. Without acceleration, it needs 3860 seconds. The acceleration rate is 191.8%. A very huge improvement!
5. Support Materials
Vision Transformer training on GPU
Vision Transformer training finished on GPU
Vision Transformer training on CPU
About this Post
This post is written by Chen Li, licensed under CC BY-NC 4.0.